emphasis
I've always been fascinated by the possibility to generate audio from text. This API provides access via REST to TTS engines like SAPI and Piper.

The frontend is very minimal, showing a basic demo
Writing an application that can create TTS is very difficult, and that was never the goal of this project. Instead I wanted to provide a simple to use way for other applications to integrate TTS into their workflow.
Main features/components
There are several (this is a comprehensive overview)
Minimal frontend for testing
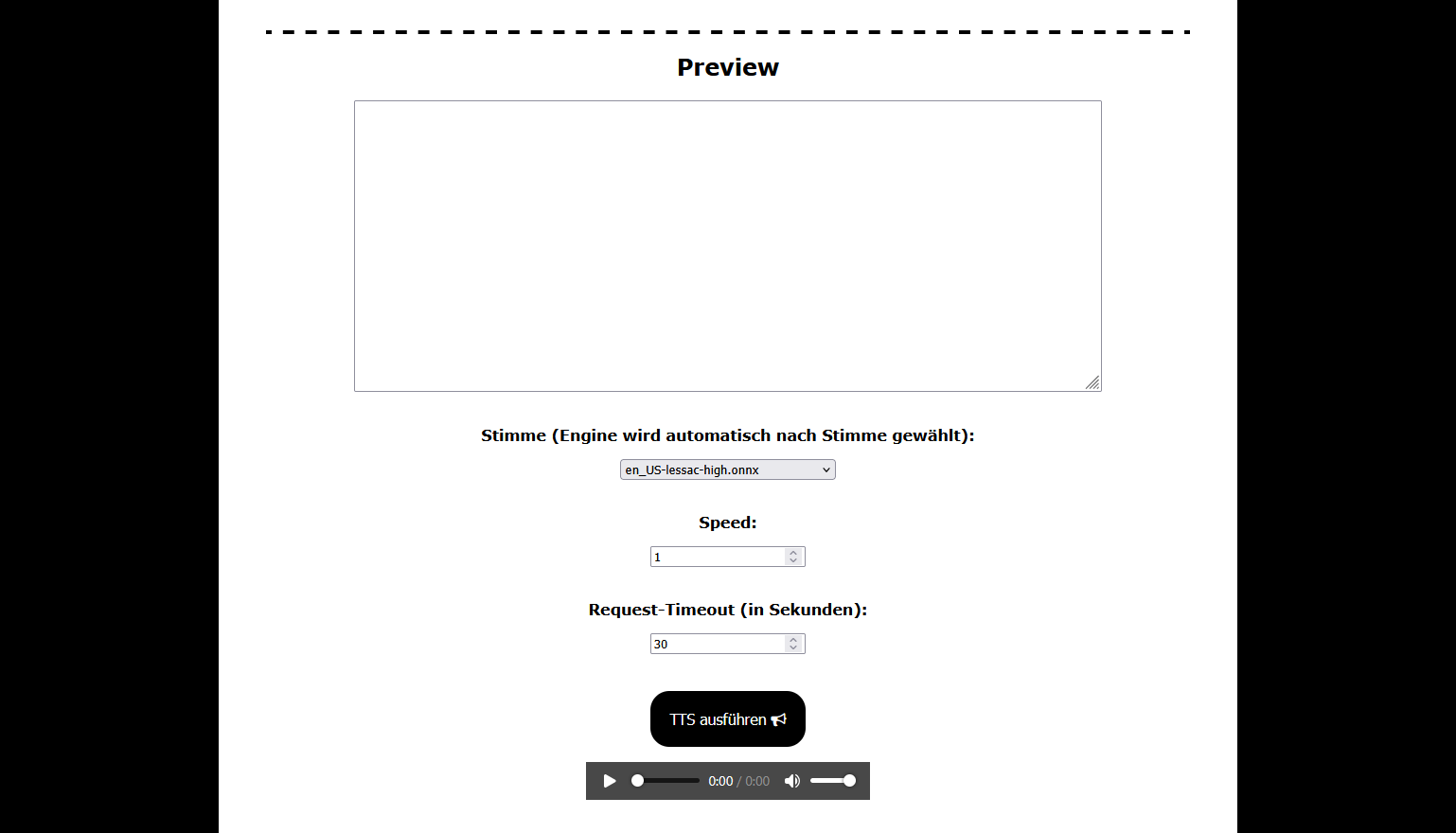
The preview section of the interface
The frontend shown in the title and in the screenshot above, only serves as a simple way to test the API 🐞. It has a text input, speed of reading, a timeout (important for large texts) and a way to play the resulting audio.
How it works
The emphasis API provides access to different TTS engines that are hosted on the same system as emphasis itself. Currently I implemented two interfaces:
- SAPI 5 (Speech Application Programming Interface) provided by Microsoft that comes with every Windows
- The Piper project that runs on Windows, Linux and Mac
Depending on the system emphasis is running on, one or both options are available (this can be configured in the settings).
For creating audio files from text, you only need to provide a JSON object inside your HTTP-POST-request:
{
"engine": "SAPI",
"voice" : "aValidVoiceName",
"speed" : 2,
"text" : "This string will be converted to audio."
}
If the request was successful, emphasis will send back a JSON object containing an url to the audio file that can be downloaded or streamed.
Some technical details
The internal workflow looks like this: First the webserver that offers the API endpoint (api.php) will receive the POST request.
After validating the given information (supported engine, available voice etc.) it will trigger a python script in the backend that talks to the locally installed TTS engine which will do it's magic to create the audio file.
The resulting file will be made available to the client.
There are some other details that I skipped here (because they are very boring), like the fact that the API will first store the given text into a temporary file that the python scripts can read from (short answer: to make the programming more convinient on multiple operating systems, due to the different syntaxes of console commands).
Other scripts take care of showing the available voices of the engines, naming the resulting audio and removing old files from the files diretory 📦.
Live Demo // Source code
I originally provided a link to my hosted instance which I use on a daily basis, but I noticed somebody flooding the API with requests. That's why I limited the access. If you want to see a demo, you can watch this video: